efficient tool selection with SLMs
efficient tool selection with SLMs
So I'm building an on-device agentic AI framework. Runs a local LLM on your phone. No cloud or API calls.
I hit a wall pretty early on - one that most people don't talk about. Tool selection is expensive on a local model.
the problem
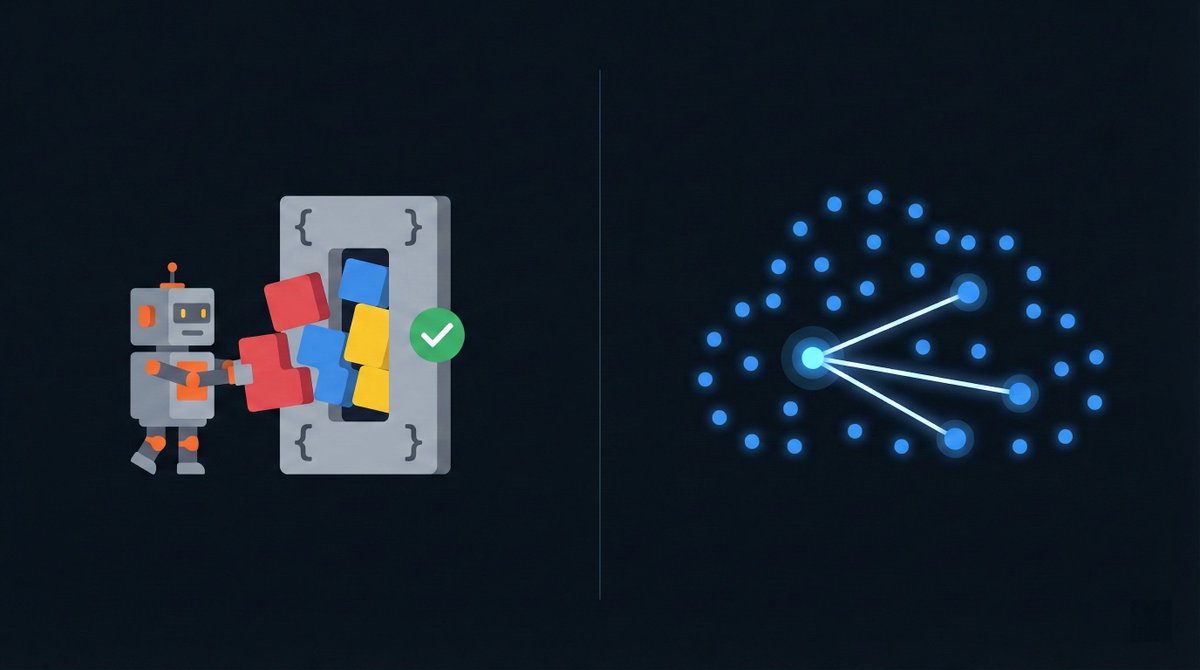
Most agentic frameworks do tool selection the same way: you shove all your tool descriptions into the system prompt, ask the LLM "which tools should I use" and pray it picks the right ones and outputs a good JSON.
But you just can't inject 50 or 100 tools into the tiny context window of these models. You also can't trust them to reliably output a complex JSON output which includes formatted parameters.
I also did try to force deterministic outputs using GBNF grammars, constrained JSON sampling, to force the output into a strict schema so the model HAS to return valid tool names. But the model still picks the wrong tools half the time. The grammar forces correct syntax, not semantics.
The traditional approach only works fine when you're calling an API and it responds in 200ms. But it doesn't work when you're running a ~1B model on a 4 year old Android.
I'm working with a system that has over 100 tools. Injecting the description, example use cases and other tool information for all of them, inside the system prompt of a small language model, is suicide.
the solution
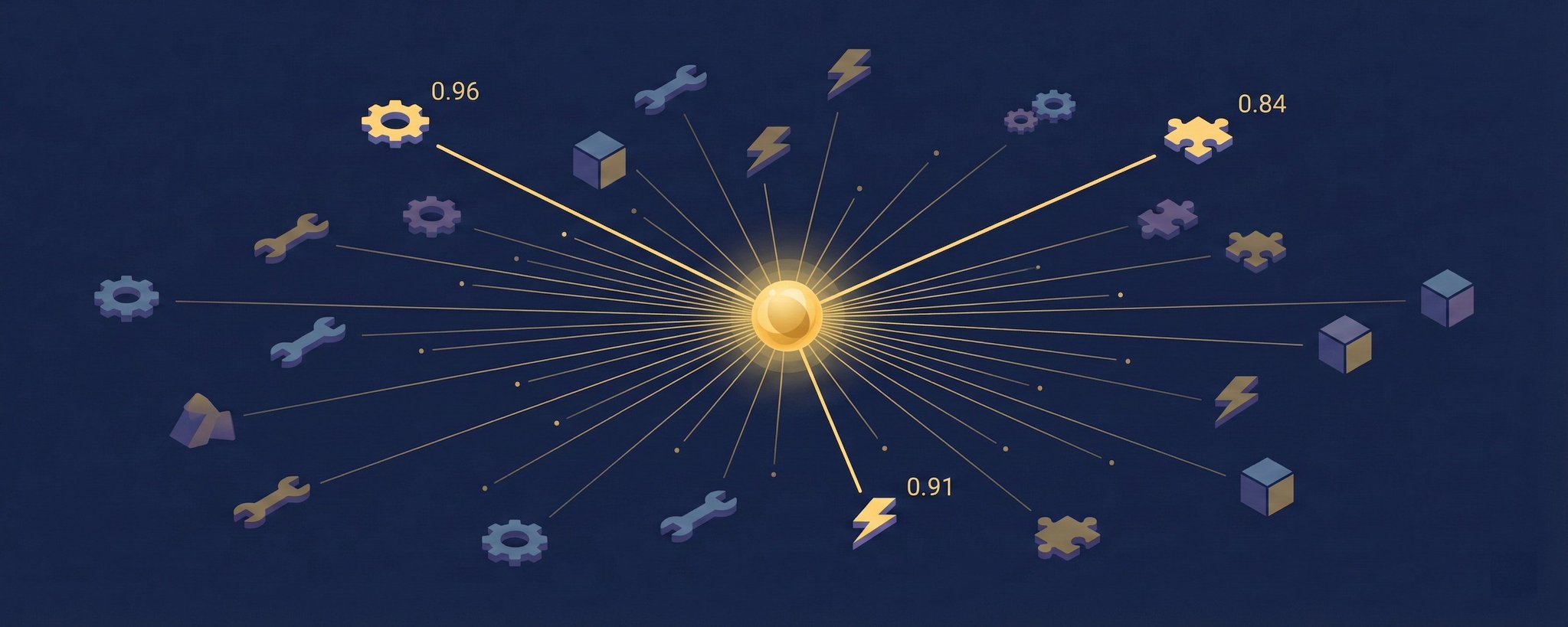
Tool selection is a matching problem. That's literally what embeddings are for.
Here's the approach I used to optimize tool selection:
-
Tools normally have only descriptions. But I went one step further. I added example queries and use-cases for each tool. I also added keywords for each.
-
I then pre-compute embeddings for the descriptions and all of these snippets using my embedding model of choice - the same one that's used in my application. I then store them in a static database that ships with the app.
-
At runtime when a user comes in, I embed just the query (one embedding call, takes ~5ms), then find similar embeddings in the static database. Then sort by score. Done.
-
The top scoring tools get selected. If any tool scores over 95%, it's force-included. Keyword matching acts as a safety net here too. If a keyword (or multiple) matches, we include that tool no matter what the embedding says.
extra enhancements

I don't just embed the current query. I built a weighted embedding system that combines:
- Current query (weight: 1.0)
- Previous user message (weight: 0.5)
- The one before that (weight: 0.25)
and so on, decaying by half each time.
The above is a simple example of how you can customize the approach to work better in conversational scenarios. This way, the system works even on follow-up questions and overall works better in multi-turn conversations!
the results
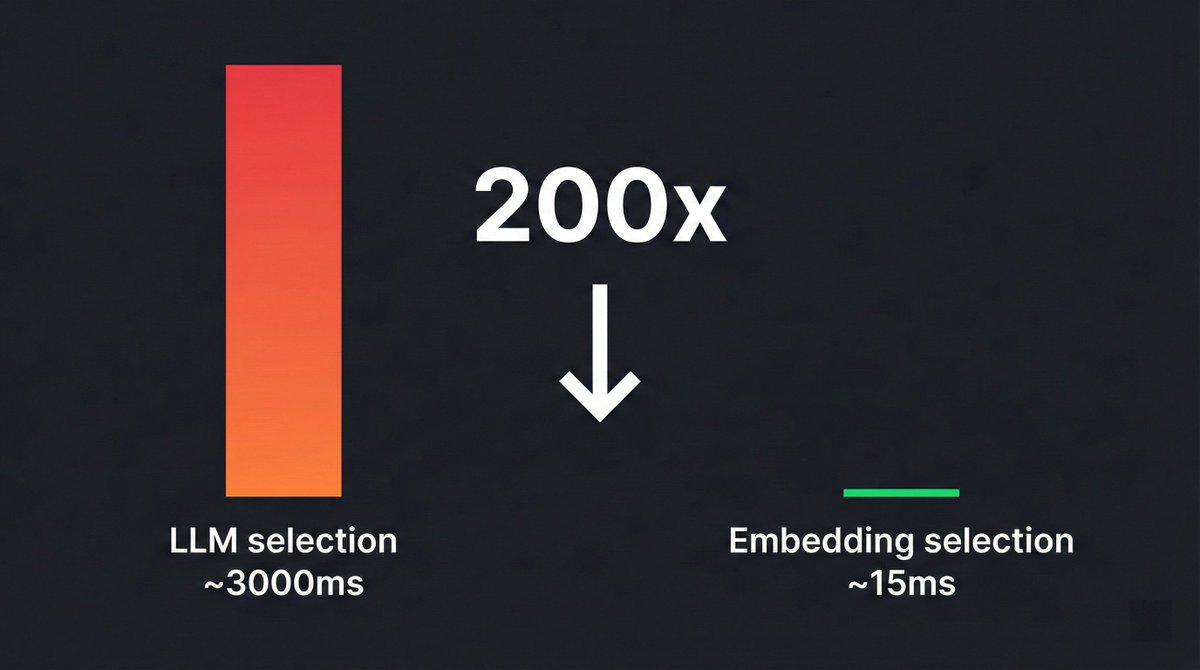
- Tool selection went from ~3-5 seconds (at least, through LLM inference) to ~15-30ms (embed + cosine similarity)
- Lesser cases of SLMs hallucinating tool names or getting confused by long prompts or context windows.
- The SLM is reserved for better work than tool selection
I still keep LLM refinement as a possible second pass. There's two ways one could go about this. If you're mainly working with tools that don't require args (like I am currently) then you can skip LLM refinement and directly execute the tools and provide tool outputs to the SLM. Else, you can provide the top 3/top 5 tools to the LLM, and ask it to pick the best ones (and if needed, provide arguments to the selected tools).
Overall, if you're building agents with too many tools, and latency matters, and you're working with constrained compute and a tight context window, try this approach. The LLM should be thinking, not matchmaking and attempting to output complex JSONs.