i built private vector search
i built private vector search

Every time you search a vector DB, you leak information.
Your query embeddings reveal your intent. Your medical questions and concerns. Your legal research. Your company's proprietary data. The server sees everything. The embedding provider and storage understands what you're storing, and what you're searching for.
We're shoving sensitive data into vector DBs more than ever. I built something that fixes this. It's called Opaque: encrypted vector search where the server can't see your query OR your vector data. A query on a DB with 100k vectors takes 172ms and has 95% top-10 recall. (Since this writeup, Opaque scaled to 99.8% Recall@10 at 464ms on 1M vectors — see the live showcase.)
Vector search has a privacy problem
Here's the reality about vector embeddings: they're not an array of random numbers. They actually encode meaning. For example, "what are the symptoms of HIV" and "HIV symptoms" produce nearly identical embeddings. If I can see your query vector, I can somewhat reconstruct what you asked. Not perfectly, but well enough to understand what you're probably searching for.
So, what does one do? There are two bad options:
- Trust the server: Your queries and data are visible. You hope attackers don't hack the server and obtain the vectors.
- Run everything locally: Run your own vector DB locally. Everything works great, until your DB has millions of vectors.
The promise of Homomorphic Encryption
There's a third option though, that cryptographers have been working on for decades, called homomorphic encryption. It lets you compute on encrypted data, without ever decrypting it.
Super cool, yeah? Here's the catch — it's slow. Like, really slow. Like, "let me grab a coffee while these dot products compute" slow. That's why nobody uses this in systems that scale.
I wanted to find a workaround though. HE is tech that allows us to do something that no other algorithm can do.
Why I built this

I've been obsessed with privacy tech for a while. The cryptography stuff, where you can actually prove that your architecture guarantees privacy. Plus, privacy is big. In both AI and web3.
I kept seeing the same gaps. Homomorphic encryption is beautiful. Elegant math. Strong guarantees. But when you try building anything at scale, it breaks. You can't have users waiting forever for a simple query.
So I wanted to know how hard it would be to make HE work for vector search.
Spoiler: it was not easy
What I built
The project is called Opaque. It is a privacy-preserving vector search system where:
- Your query is encrypted with homomorphic encryption
- Your vector data is encrypted with AES-256
- The server computes on ciphertext and learns nothing.
- Results are decrypted locally on your machine.
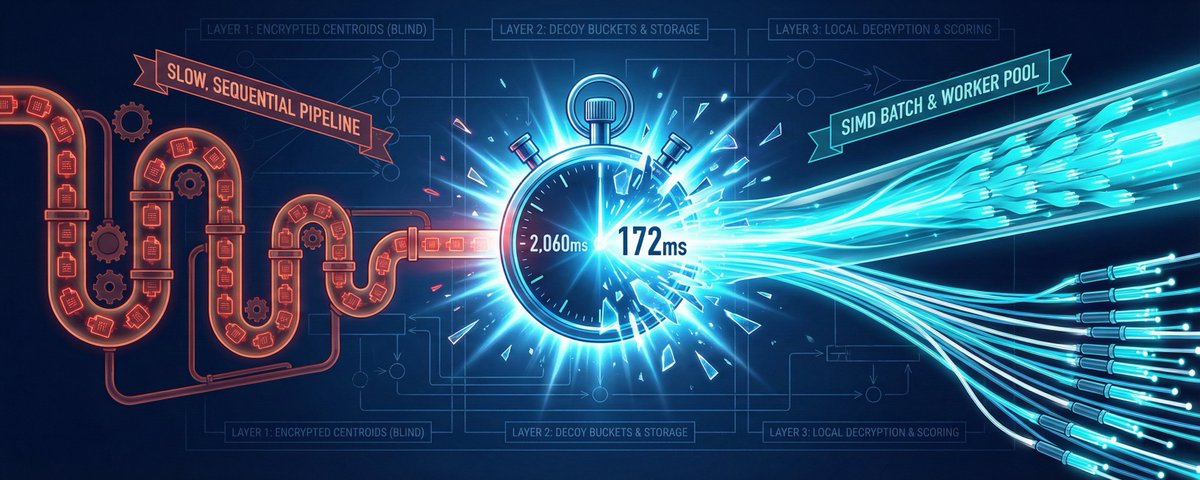
The result? A query on 100k vectors runs in 172ms with 95% top-10 recall.
Is that as fast as plaintext search? No. Plaintext does this in under 50ms, or sometimes even under 20ms. But 172ms is quite usable. Especially in agentic use-cases, where users wait many seconds before getting an answer. And unlike plaintext, the server and database see nothing.
The Python Disaster

I started where most people start: Python. Found a library called LightPHE - this wasn't fully homomorphic encryption, but it was a good starting point, and I saw a paper where the author of this repository used it to perform encrypted vector similarity search. Clean API and good docs. I got a prototype working in a few hours.
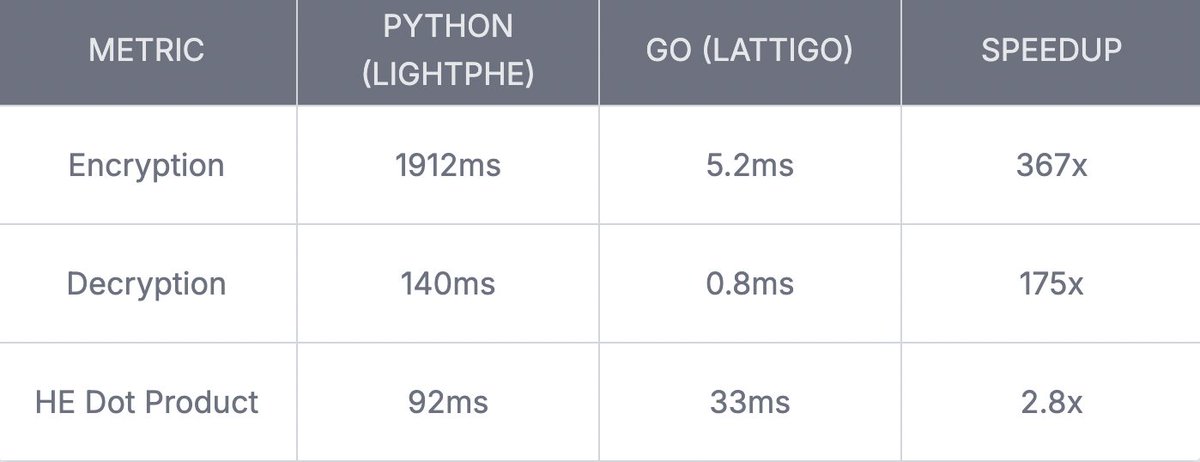
Then I benchmarked it.
6.5 seconds per query.
That's not a search engine. That's a meditation exercise.
I tried everything to optimize this. Caching. Batch operations. Smaller HE parameters. Nothing changed. Python's overhead was killing me.
Maybe HE was really "too slow for practical systems".
The discovery
Then I found lattigo. It's a Go library for lattice-based cryptography, written by researchers at EPFL. It implements CKKS, BFV, and other HE schemes.
But how much faster could it really be? 2x? 5x?
I ported my benchmark and ran it. I added parallelism.
367x faster at encryption.
Python wasn't just slower. It was making this project impossible. Go made it possible. HE was embarrassingly parallel, and that helped too.
I rewrote everything in Go that week.

BFV vs CKKS
I wanted to dig deeper into homomorphic encryption, and understand what's actually happening.
HE has different "schemes" — ways of encoding data so you can compute on it. I had to choose between:
- BFV: Works on integers. Exact arithmetic. But vectors are floats, not integers. I'd have to encode floats as scaled integers, do the math, then decode.
- CKKS: Works on approximate floats directly. Some noise accumulates with each operation. But for similarity ranking, where we just need to know "A is more similar than B" - approximate is fine.
I went with CKKS, and it ended up being the perfect decision. CKKS encodes floating-point numbers into polynomial rings. You can add and multiply these polynomials. The results are "noisy" - they're not exact, but are close enough. For similarity ranking, this is what we need. Relative ordering survives the noise.
The working prototype
Here's what I did to get things working:
- Created a 128-dimensional query vector.
- Encrypted it with CKKS (5ms)
- Sent the ciphertext to my test server
- Server computed encrypted dot products with 10 test vectors
- Server returned encrypted similarity scores
- I decrypted the scores locally (0.8ms)
- Compared to plaintext computation
The scores matched within 0.1%. The server never saw my query. It never saw the results either.
It actually worked.
Real cryptographic privacy. Real computation. Real results.

But I Wasn't Done
At this point, I had a working prototype. Query-private vector search. ~66ms latency for top-10 results. Server couldn't see what I was searching for.
But there was a problem. I was solving for one thing - hidden queries. The server/database still saw all my vectors in plaintext. If someone breached the server, they'd get everything.
Query privacy doesn't help if your data is sitting there unencrypted. I wanted to hide the query AND the data.
Hiding the data too
The next iteration: encrypt the vectors at rest with AES-256. Server/DB stores encrypted blobs. Can't read them. I hold the keys.
Now even if the server gets breached, attackers get encrypted garbage. Progress.
But there was still a problem: in this mode, the query was visible. Server knew what I was searching for. I was protecting data, but leaking intent.
I wanted both.
Hiding everything
This is where it got interesting. I needed to combine HE (for query privacy) with AES (for data privacy) without the server learning anything from either.
This part of the project is what taught me the most. I architected a system that balances privacy, speed and accuracy. This was the holy grail of encrypted vector search.
The solution was a three-layered approach where each layer plugs the privacy holes of the others.
The three-layer architecture
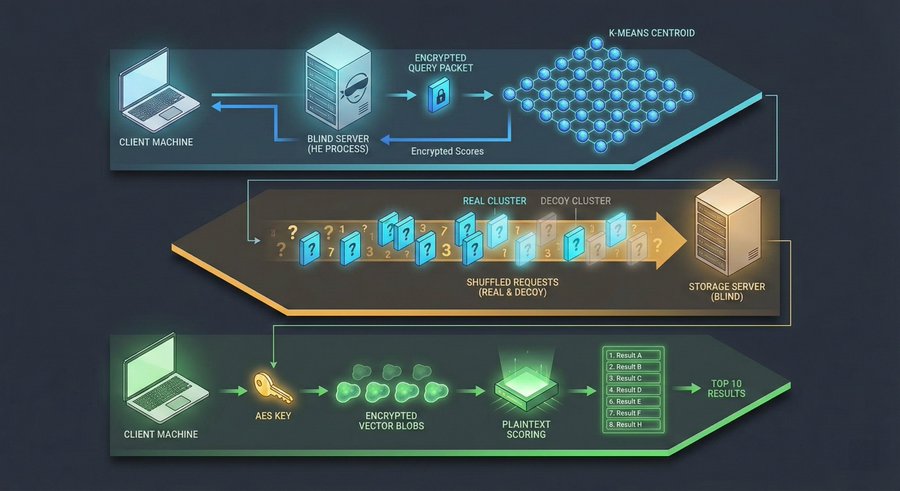
Layer 1: HE Centroid Scoring
Your query is encrypted with homomorphic encryption. The server has 64 centroids - think of these as "regions" of your vector space. The server computes encrypted dot products with all centroids. You decrypt locally and pick which clusters to search.
The server never sees which clusters you chose. It just did math on ciphertext and returned ciphertext.
Layer 2: Decoy-based bucket fetching
You request vectors from your chosen clusters. But you also request "decoy" clusters - random ones you don't care about. Server can't tell real from fake. Returns encrypted vector blobs for all of them.
Even if the server logs access patterns, it sees a mix of real and fake requests. Plausible deniability.
Layer 3: Local AES decryption + Scoring
You decrypt vectors locally with your AES key. Compute final scores on your machine. The results never leave your device.
The server has no idea what you found, and what the top vectors were.

The server sees encrypted blobs. The storage sees encrypted fetches mixed with decoys. You see your results.
Privacy preserved.
The problem: 2 seconds per query
There was just one problem with this beautiful architecture.
2 seconds per query.
That's not a search engine. That's a loading screen.
The bottleneck? HE centroid scoring. Computing 64 encrypted dot products was taking 1760ms. Everything else was fast. This one step was killing the entire system.
Here's how I fixed it.
Optimization 1: SIMD Batch HE (The Big One)
CKKS has this concept of "slots". When you encrypt a vector, you're not just encrypting a set of numbers — you're filling up a polynomial ring with up to 16,384 values.
I was encrypting 128-dim vectors. Using 128 slots. The other 16,256 slots are asleep. Empty. Wasted.
That's like buying a commercial plane for a family of four.
So I packed all 64 centroids in a single ciphertext. One homomorphic multiply scored all of them at once.
Before: 64 sequential dot products = 1760ms After: 1 batched operation = 28ms
The result? 62x speedup (!)

Optimization 2: Worker Pool Parallelization
Lattigo's evaluator (the part that does HE operations) is not thread safe. But you can create multiple evaluators that share the same keys.
So I built a worker pool. 10 parallel crypto engines. Fed them all the operations, and collected results.
Before: 330ms for 10 dot products (sequential) After: 56ms (parallel, 10-core M4 Air)
Turns out you can just... use more cores. Revolutionary.
Optimization 3: K-Means over LSH
My first prototype used Locality-Sensitive Hashing (LSH) to assign vectors to buckets. LSH uses random hyperplanes to hash vectors-similar vectors to get similar hashes. Simple and fast.
But LSH centroids are random projections, and don't actually represent cluster centers. When the server scores my encrypted query against LSH centroids, it's comparing against random directions, and not meaningful representations.
So I replaced LSH with k-means clustering. K-means centroids are actual cluster centers. They literally minimize the distance to their assigned vectors.
Before (LSH): 83% cluster hit rate — this means that almost 1 out of 5 times, the best vectors weren't in the selected buckets! After (k-means): 98% cluster hit rate
That's the single biggest accuracy improvement in the project. Better indexing always beats better scoring.
Optimization 4: Redundant Assignment + Multi-probe
Even with k-means, boundary vectors are a problem. If a vector sits right between two cluster centers, it gets assigned to one. If your query is closer to the other center, you miss it!
Two fixes for this:
-
Redundant cluster assignment: Assign each vector to its top 2 nearest clusters, not just the closest one. Now the boundary vectors will exist in both clusters. 2x storage overhead, but boundary queries stop missing results. Remember, our architecture is not trying to optimize for storage, but speed and accuracy. This is an acceptable tradeoff!
-
Multi-probe selection: When selecting which clusters to search, don't just take the top K by score, but also include any cluster whose score is within 95% of the k-th cluster's score. CKKS computations add noise - and this means that scores are approximate! A cluster that scored slightly below the cutoff might actually be relevant.
The result? Recall jumped from ~80% to 95%! These two techniques handled the edge cases that k-means alone misses!
Final Results

172ms with 95% Recall@10 (!)
Is it as fast as plaintext search? Not even close. Plaintext does this in about 10ms.
But 172ms is very usable. That's faster than a lot of API calls, even. And unlike plaintext, neither the server nor the database can see anything.
Honest Assessment
172ms. 95% recall. Full cryptographic privacy. But this project is far from perfect.
What Actually Works
-
95% recall@10: Out of every 10 results, you get the right ones 95% of the time. For most applications, that's good enough.
-
172ms latency: Sub-200ms for full cryptographic privacy. Usable for real applications. Not great for real-time autocomplete, but fine for search-and-click interfaces.
-
Post-quantum secure: The underlying crypto (RLWE - Ring Learning With Errors) is based on lattice problems. These are believed to be hard even for quantum computers. Your data stays private even when quantum computers arrive.
What's Broken

-
Performance: Still ~17-170x slower than plaintext search. Plaintext does this in 1.7 - 17ms (approx). Homomorphic encryption has a huge overhead, and there's no way to get around that. For a real-time system, this is unusable.
-
Cluster Access Patterns: The server knows which clusters you request (even though it doesn't know which ones are real vs decoy). With enough queries over time, an adversary could analyze access patterns to infer which clusters are being queried regularly. If you always request the same real clusters, statistical analysis might filter out the noise.
Missing Features
-
Auth service: Key distribution is manual right now. No proper rotation or revocation.
-
Dynamic cluster rebalancing: K-means clusters are static after build time. As data distribution shifts, cluster quality degrades. Need online rebalancing without re-encrypting everything.
Threat Model Gaps
There are things I can't protect against:
-
Malicious Server: If the server actively lies about computation, I can't detect it. It could return random garbage instead of real scores. Would need SNARKs to verify. Someday, not today.
-
Statistical Analysis: With enough queries over time, patterns might emerge. If you search for similar things repeatedly, an attacker may identify which clusters correspond to what type of data. Nevertheless, the data is all encrypted. Not too much to worry about here.
Final Thoughts
If you're a cryptographer and you see any fundamental issues with this architecture, then please let me know! You can also open an issue or put up a PR in my repo.
This is a research project - a prototype, that works. Not a production level system. Yet.
What I Learned
-
Homomorphic encryption is hard but not impossible for practical systems. Everyone told me HE was slow. It is, but there's ways around that limitation.
-
The gap between papers and code is huge. Research papers describe elegant algorithms. They don't describe the memory management, the serialization formats, the parameter tuning, the off-by-one errors in polynomial degree calculations.
-
Privacy has a cost. And sometimes it's worth paying. 172ms is 1,700x slower than plaintext. For a medical records search? Worth it. For a public movie database? Maybe not. Know your threat model.
Come build with me. The repo is open here. The code is messy in places. But you can fix it!

The Future of Private AI
Here's what I believe. As AI eats more of the world, the privacy problem gets worse. More data in embeddings. More queries revealing intent. More servers you don't control seeing things you don't want them to see.
We need cryptographic solutions that actually work. Solutions where the math itself guarantees privacy.
Project Opaque is an attempt at this. It's not perfect, nor is it production-ready. The performance has room to improve. The threat model has a few gaps.
But it works. 172ms. 95% recall. Full cryptographic privacy. A real system, not just a hypotheses.
I'm building this in public because I think privacy tech should be open. If someone improves on this - great! If someone finds a flaw and breaks it? I'd rather know. If this inspires someone smarter to build something better? Mission accomplished.
Let's make privacy in AI actually work.
Thanks for reading!
References
- CKKS.org
- Lattigo library
- Encrypted Vector Similarity Computations Using Partially Homomorphic Encryption: Applications and Performance Analysis
- LightPHE library
- Analysis of k-means for IVF-style vector indexing - the same approach Project Opaque uses for cluster assignment, achieving 98% hit rate over LSH's 83%.
- LSH: The Illustrated Guide
- Code for Project Opaque